
107
MÉTODOS DE CLASIFICACIÓN EN MINERÍA
DE DATOS METEOROLÓGICOS
Methods of Classication in Mining of Meteorological Data
1
Silvia Haro Rivera*,
1
Lourdes Zúñiga Lema,
2
Antonio Meneses Freire,
1
Luis Vera Rojas,
1
Amalia Escudero Villa
*s_haro@espoch.edu.ec
R
esumen
A
bstract
Uno de los objetivos de la minería de datos es la clasicación, la cual tiene como n clasicar una variable
dentro de una de las categorías de una clase. En este trabajo se consideraron variables meteorológicas de
la estación Cumandá. Con el objetivo de determinar el modelo adecuado al conjunto de datos, se apli-
caron los modelos de clasicación : Naive Bayes, CN2 Rule Induction, K-NN, Tree y Random Forest;
así como también los métodos que modican los parámetros asociados al clasicador: Cross validation,
Random sampling , Leave one out y Test on train data . Mediante el software Orange Canvas se
calcularon las medidas de rendimiento , Classication Accuary , Precisión Global y Sensibilidad . Se
concluyó que los clasicadores Naive Bayes , CN2 Rule Induction y K-NN presentaron valores
superiores al 75% de instancias correcta- mente clasicadas. El árbol de decisión y el Bosque Aleatorio
superaron el 80%. En cuanto a los métodos que permiten modicar los parámetros asociados al
clasicador se determinó que Validación Cruzada, presentó mejores resultados en todas las aplicaciones.
La mayor precisión se alcanza en el clasicador bosque aleatorio, con un 83.9% aplicando validación
cruzada, seguido por el muestreo aleatorio simple con un porcentaje del 83.1% de verdaderos positivos
entre los casos clasicados como positivos.
Palabras claves: métodos de clasicación, minería de datos, datos meteorológicos.
Keywords: classication methods, data mining, meteorological data.
Fecha de recepción: 08-06-2018 Fecha de aceptación: 22-10-2018
One of the colectivamente of data mining is classification, which aims to classify a variable within
one of the categories of a class. In this work, meteorological variables of the Cumandá station were
considered . In order to determine the appropriate model for the data set, the Naive Bayes , CN2
Rule Induction, K-NN, Tree and Random Forest classification models, as well as Cross validation ,
Random sampling , Leave one out and Test on train data, that modify the parameters associated
with the classifier, were applied. Orange Performance software was used to calculate performance
measures , Classification Accuary , Global Accuracy and Sensitivity . It was concluded that the
classifiers Naive Bayes , CN 2 Rule Induction and K-NN presented values higher than 75% of
correctly classified instances. The decision tree and the Random Forest exceeded 80%. Regarding
the methods that allow to modify the parameters associated to the classifier, it was determined that
Cross-validation presented better results in all the applications. The highest precision is reached in
the classifier random forest with 83.9% applying cross -validation , followed by simple random
sampling with 83.1% of true positives among the cases classified as positive.
1
Escuela Superior Politécnica de Chimborazo, Riobamba. Ecuador
2
Universidad Nacional de Chimborazo, Riobamba, Ecuador

108
Revista Cientíca
I. INTRODUCCIÓN
La minería de datos como herramienta estratégica es
clave para explotar el conocimiento de los datos, su
objetivo es analizarlos desde todas las perspectivas es-
tratégicas, con el n de transformar la información y el
conocimiento. Mediante la minería de datos se puede:
ordenar, clasicar, ltrar y resumir todas las relacio-
nes que un dato puede tener dentro de la información,
está centrada no solo en extraer conocimiento sino en
encontrar las relaciones o correlaciones que la informa-
ción; vista desde diferentes (1) ámbitos, tiene con otros
datos aparentemente no conectados y, generalmente,
recogidos en enormes bases de datos relacionales. La
minería de datos en variables meteorológicas tiene una
gran aplicación e interés en la actualidad; pues, brinda
alternativas diferentes a los métodos tradicionales de
análisis y permite estimar variables diversas en casos
especícos (2). En este trabajo, primero se realiza un
enfoque teórico de cinco clasicadores en minería de
datos: Naive Bayes, CN2 Rule Induction, K-NN, Tree
y Random Forest; así como, los parámetros para eva-
luar el rendimiento de cada uno de estos y los méto-
dos que permiten modicar al clasicador. Segundo,
mediante el software Orange Canvas se realiza la apli-
cación; y tercero, se analizan los resultados y emiten
conclusiones.
Clasicadores
La clasicación en minería de datos es una técnica super-
visada, donde generalmente se tiene un atributo llamado
clase y se busca determinar si los atributos pertenecen o
no a un determinado concepto (3).
La clasicación, es la habilidad para adquirir una fun-
ción que mapee (clasique) un elemento de dato a una de
entre varias clases predenidas. Un objeto se describe a
través de un conjunto de características (variables o atri-
butos) X→{X
1
, X
2
,…, X
n
}. El objetivo de la tarea de
clasicación es clasicar el objeto dentro de una de las
categorías de la clase C = {C
1
,…, C
k
}
f: X
1
x X
2
x … x X
n
→ C
Las características o variables elegidas dependen del pro-
blema de clasicación. Para el estudio se consideraron
los siguientes clasicadores:
Naive Bayes
La clasicación mediante el algoritmo
Bayesiano ofrece la solución óptima de
la probabilidad de pertenencia de cada
muestra a todas las clases. De acuerdo
a la teoría general de la probabilidad de
Bayes, dado x el objetivo es asignar x a
alguna de las clases existentes. Supónga-
se que las clases son S
1
, S
2
, …, S
c
; para
cada una de ellas se puede estimar la fun-
ción de densidad de probabilidad, por lo
que para la observación x se trata de de-
terminar la probabilidad a posteriori de
que dicha muestra pertenezca a la clase
S
j
, misma que se puede calcular por:
Donde (m
j
, C
j
) es la función de densidad
P(S
j
| x) =
P(x | m
j
, C
j
)P(S
j
)
∑
(j=1)
P(x | m
j
, C
j
)
c
de probabilidad para la clase S
j
(4).
CN2 Rule Induction
El algoritmo CN2 es una técnica de cla-
sicación diseñada para la inducción e-
ciente de reglas sencillas y comprensi-
bles de forma “si entonces”, este modelo
funciona solo para clasicar. La búsque-
da de reglas puede ser por:
• Medida de evaluación, selecciona
una regla heurística para evaluar las
hipótesis encontradas; puede darse
por: entropía (medida de la imprevi-
sibilidad del contenido), mediante la
precisión de Laplace o por una preci-
sión relativa ponderada.
• Ancho del haz, recuerda la mejor regla
encontrada hasta el momento y moni-
torea un número jo de alternativas.
K-NN o Nearest Neighbours (Vecinos
más cercanos)
El método K-NN emplea la clasicación
supervisada estimando la distancia de
cierto número de muestras (K vecinos)
Número 20 Vol. 2 (2018)
ISSN 2477-9105

109
a la muestra que se pretende clasicar,
determinando su pertinencia a la clase
de la que encuentre más vecinos etique-
tados, considerando el criterio de míni-
ma distancia. Esta técnica es válida solo
para datos numéricos, no para clasica-
dores de textos (5). Dado un conjunto
de muestras X = {x
1
, x
2
, …, x
n
}ϵR
p
con
función de distancia d, se tiene:
1. Vecino más cercano: localizar la
muestra x
l
en X más cercana a x
k
, con
l ≤ k ≤ N y k ≠ 1.
2. Rango r: dado un umbral r y n punto
x
k
, no considerará los puntos x
l
que
satisfacen 0 ≤ d(x
k
, x
l
) = d
kl
≤ r.
Tree (Árboles de decisión)
Es una técnica de clasicación supervi-
sada (6), permite determinar la decisión
que se debe tomar siguiendo las con-
diciones que se cumplen desde la raíz
hasta alguna de sus hojas (7). El árbol
de decisión se construye partiendo el
conjunto de datos en dos o más subcon-
juntos de observaciones, después estos
subconjuntos se vuelven a particionar
empleando el mismo algoritmo. La raíz
del árbol es el conjunto de datos inicial,
los subconjuntos y subsubconjuntos
conforman las ramas del árbol. El con-
junto en el que se realiza una partición
se llama nodo y permite bifurcar en fun-
ción de los atributos y sus valores. Las
hojas del árbol proporcionan prediccio-
nes. Los algoritmos más utilizados son:
ID3, C4.5 y CART (8)
Random Forest (Bosque aleatorio)
Es una combinación de árboles predic-
tivos, el cual trabaja con una colección
de árboles incorrelacionados y los pro-
media; de modo que cada árbol depende
de los valores de un vector aleatorio de
la muestra de manera independiente y
con la misma distribución de todos los
árboles en el bosque (6). Random Forest
o “Selvas Aleatorias” es una técnica pre-
dictiva en la cual todos los clasicadores
del método del consenso (Bagging) son árboles de deci-
sión. Cada modelo genera una predicción y se selecciona
por la mayor cantidad de votos (8).
Evaluación de los clasicadores
Para evaluar los clasicadores se consideraron los si-
guientes parámetros (9):
Classication acccuary (CA): Determina la proporción
de ejemplos correctamente clasicados.
Precisión y exactitud: La primera se reere a la disper-
sión del conjunto de valores obtenidos de mediciones re-
petidas de una magnitud. Cuanto menor es la dispersión
mayor la precisión; y la segunda, se reere a cuán cerca
del valor real se encuentra el valor medido. En términos
estadísticos, la exactitud está relacionada con el sesgo de
una estimación. Cuanto menor es el sesgo más exacta es
una estimación. Estos indicadores de precisión se pueden
calcular por:
Precisión =
tp
tp + fp
Exactitud =
tp + tn
tp + tn + fn + fp
Recall (sensibilidad o exhaustividad): es la proporción
de verdaderos positivos entre todos los casos positivos en
los casos. Si su resultado es uno entonces se han encon-
trado verdaderos positivos en la base de datos, por lo que
no existiría ruido ni silencio informativo. Por el contrario
si su valor es cero los datos no poseen relevancia alguna.
Se calcula por:
Recall =
tp
tp + fn
Matriz de confusión
La matriz de confusión permite la visualización del
desempeño de un algoritmo que se emplea en aprendiza-
je supervisado. Las columnas representan el número de
predicciones de cada clase, mientras que cada la repre-
senta las instancias en la clase real (9). A continuación
se muestra la matriz de confusión para el caso donde se
tienen dos clases.

110
Revista Cientíca
Predicción
Negativo Positivo
Valor
Real
Negativo VN (verdadero negativo) FP (falso positivo)
Positivo FN (falso negativo VP (verdadero positivo
Tabla 1. Matriz de confusión, dos clases
Métodos para modicar los parámetros
Los métodos utilizados para modicar los parámetros
asociados al clasicador fueron:
Cross validation: validación cruzada es una técnica uti-
lizada para evaluar los resultados de un análisis estadís-
tico y garantizar que son independientes de la partición
entre datos de entrenamiento y prueba (10). En Orange
Canvas el algoritmo divide al conjunto de datos en plie-
gues (generalmente entre 5 o 10). El algoritmo se prueba
manteniendo ejemplos de un pliegue a la vez, el modelo
se induce de otros pliegues y se clasican ejemplos del
pliegue retenido. Esto se repite para todos los pliegues.
Random sampling (muestreo aleatorio simple): divide
aleatoriamente los datos en el entrenamiento y el conjun-
to de pruebas en la proporción jada por el usuario, se re-
pite el proceso durante el número especicado de veces.
Leave one out: es similar al cross validation pero tie-
ne una instancia a la vez, induce el modelo de todos los
demás y luego clasica las instancias presentadas. Este
método es muy estable, able pero lento.
VARIABLE DESCRIPCIÓN
DÍA Día
MES Mes
AÑO Año
HORA Hora
TEMP Temperatura
HUMREL Humedad relativa
PREBARO Presión Barométrica
RADIFU Radiación difusa
RSG Rediación solar global
TEPSU Temperatura del suelo
VV Velocidad de viento
Tabla 2. Variables de estudio
Test on train data: utiliza todo el con-
junto de datos para el entrenamiento y
luego para la prueba; este método siem-
pre da resultados erróneos.
Test on test data: este test permite in-
troducir otro conjunto de datos con
ejemplos de prueba (desde otro archivo
o seleccionados en otro enlace).
II. METODOLOGÍA
Los datos empleados en este trabajo
corresponden a registros por día y hora
(00:00 a 23:00) durante los 12 meses del
año 2015. El chero de datos contiene
92 136 observaciones y las variables se
detallan en la tabla 2.
Se generó la variable categórica ESCA-
LA considerando intervalos de tiempo
con las siguientes restricciones:
• Escala-I: horas comprendidas entre la
01:00 y 06:00
• Escala-II: horas comprendidas entre
la 07:00 y 12:00
• Escala-III: horas comprendidas entre
las 13:00 y 18:00
• Escala-IV: horas comprendidas entre
las 19:00 y 00:00
El objetivo del análisis es aplicar las téc-
nicas de clasicación en la base de datos
descrita, mediante el programa Orange
Canvas y determinar los factores que
caracterizan los grupos horarios pro-
puestos. Los pasos aplicados fueron los
siguientes:
1. Carga del chero en el software Oran-
ge Canvas
2. Selección de la variable objetivo de
estudio ESCALA
3. Aplicación de los métodos de clasi-
cación
4. Evaluación de los métodos de clasi-
cación
Número 20 Vol. 2 (2018)
ISSN 2477-9105

111
Clasicador Test de prueba C.A. (%) Precisión Recall (5)
Naive Bayes
Cross validation 78,0 74,3 72,2
Random samping 77,8 75,0 77,8
Leave one out 77,9 75,2 72,1
Test on train data 75,3 77,9 72,3
CN2 Rule Induccion
Leave one out 78,2 73,2 80,2
Test on train data 100 100 100
K-NN
Cross validation 78,6 81,0 79,7
Random samping 77,9 80,6 79,6
Leave one out 78,5 80,8 80,0
Test on train data 100 100 100
Tree
Cross validation 82,1 80,3 78,4
Random samping 81,7 80,0 78,8
Leave one out 82,3 80,2 78,0
Test on train data 96,2 96,4 94,7
Random Forest
Cross validation 84,7 83,9 81,1
Random samping 84,7 83,1 81,9
Leave one out 84,9 83,9 82,4
Test on train data 97,6 97,4 96,5
Tabla 3. Resultados de los clasificadores.
III. RESULTADOS Y DISCUSIÓN
Los resultados obtenidos se muestran
en la tabla 3; donde se pueden observar
los porcentajes obtenidos en los tres pa-
rámetros de evaluación de cada uno de
los clasicadores empleados y para cada
prueba.
En la tabla 4, se muestra las matrices
de confusión de los clasicadores: Nai-
ve Bayes (NB), K-NN, Random Forest
(RF) y Tree, (T); para el caso particular
donde el parámetro que modicó al cla-
sicador fue Cross validation.
La matriz de confusión (Tabla 4) mues-
tra que, para el modelo Naive Bayes de
PREDICCIÓN
escala-I escala-II escala-III escala-IV
NB K-NN RF T NB K-NN RF T NB K-NN RF T NB K-NN RF T
Valor
actual
escala-1 1678 1761 1813 1744 398 332 276 339 0 0 0 0 18 1 5 11
escala-II 443 379 356 410 1511 1669 1669 1642 132 18 21 19 8 28 18 23
escala-III 0 0 0 0 41 13 14 21 1776 1718 1844 1772 327 363 236 301
escala-IV 124 75 9 16 57 46 35 42 296 535 311 315 1617 1438 1739 1721
Tabla 4. Matriz de confusión: Naive Bayes, K-NN, Random Forest y Tree. Cross validation
los 2094 datos del grupo escala-I; 1678 se clasicaron
correctamente, 398 se han clasicado en escala-II y 18 en
escala-IV. Además; 1511 de escala-II, 1726 de escala-III
y 1617 de escala IV también se han clasicado correcta-
mente dentro de sus respectivos grupos con igual número
de datos. En el clasicador K-NN, se puede observar que
el mayor porcentaje de datos correctamente agrupados en
su grupo corresponde a escala-I con un valor del 84.1%
y el menor es de escala IV con el 68.7%. En Random Fo-
rest (RF), el mayor número de datos correctamente clasi-
cado en su grupo es escala-III; y en el modelo Tree (T),
fue escala-III, seguido por escala-I.
El árbol de decisión (tree) se generó con cuatro niveles de
profundidad y se muestra en la gura 1.
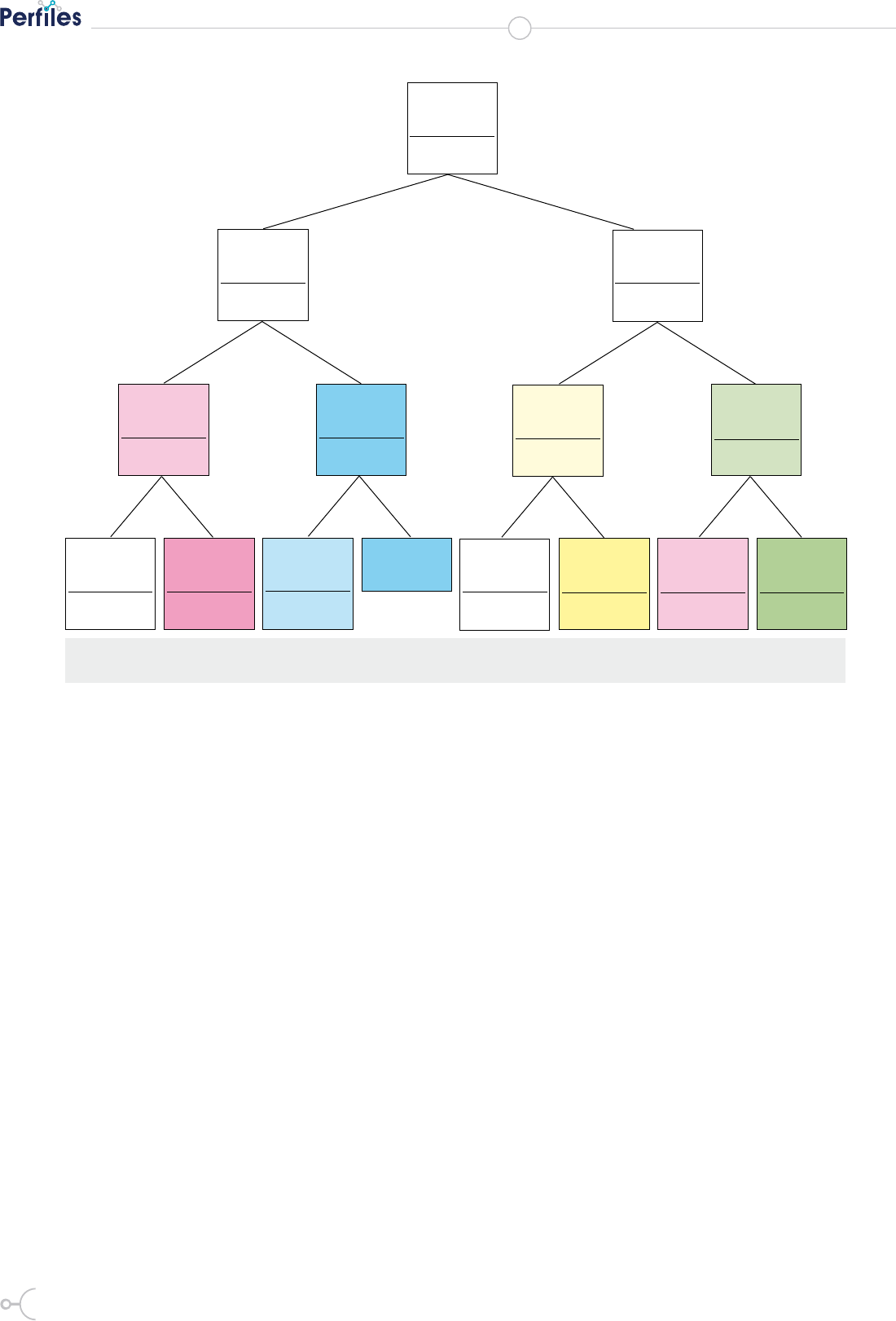
112
Revista Cientíca
escala-I
97,6%, 735/75
escala-I
53,5%, 693/12
PREBARO
escala-II
84,1%, 997/11
PREBARO
escala-I
78,6%, 474/60
HUMREL
escala-II
39,4%, 137/34
RADIFU
escala-IV
83,4% 1696/2
RSG
escala-II
70,7%, 210/29
TEMP
escala-III
87,3%, 1622/1
PREBARO
escala-II
64,4%, 1600/2
HUMREL
escala-I
89,2%, 1209/1
TEMP
escala-IV
75,1%, 1788/2
TEMP
escala-II
76,0%, 1638/2
RADIFU
escala-I
54,4%, 2089/7
TEMP
escala-III
46,2%, 2094/4
PREBARO
escala-I
25,0%, 2094/8
RSG
≤ 98,245 > 98,245 ≤ 23,670 > 23,670 ≤ 23,279 > 23,279 ≤ 14,488 > 14,488
≤ 23,017 > 23,017 ≤ 974,770 > 974,770
≤ 0,252 > 0,252
Figura 1: Árbol de decisión
De acuerdo al árbol obtenido se puedo establecer que:
si la radiación solar global (RSG) es mayor que 0.252
entonces predice la presión barométrica (PRESIBARO)
dentro de la escala III; esto es, en el horario de 13:00 a
18:00. De similar forma, si la radiación solar global es
menor o igual que 0.252 predice la temperatura (TEMP),
en el horario de 01:00 a 06:00 (escala-I). De igual manera
se puede interpretar las ramas inferiores del árbol.
IV. CONCLUSIONES
De la tabla 2 podemos concluir que los clasicadores
Naive Bayes, CN2 Rule Induction y K-NN presentan
valores superiores al 75% de instancias correctamen-
te clasicadas. El árbol de decisión (Tree) y el bosque
aleatorio (Random forest) superaron el 80%. En cuanto
a los métodos que permiten modicar los parámetros
asociados al clasicador se pudo determinar que vali-
dación cruzada (Cross validation), es el que presenta
mejores resultados en todas las aplicaciones. La mayor
precisión se presentó en el bosque aleatorio. Los resul-
tados del test on train data en los clasi-
cadores CN2 Rule Induction y K-NN
son del 100%, pero no son conables
pues emplean todo el conjunto de datos
para el entrenamiento y luego para la
prueba. La mayor precisión se alcanza
en el clasicador bosque aleatorio, con
un 83.9% aplicando validación cruzada,
seguido por el muestreo aleatorio sim-
ple con un porcentaje del 83.1% de ver-
daderos positivos entre los casos cla-
sicados como positivos. En el mismo
caso se determinó que la proporción de
verdaderos positivos entre todos los ca-
sos positivos en los casos (sensibilidad)
es mayor en el mismo clasicador. Se
pudo evidenciar que los resultados en
los clasicadores mediante los diferen-
tes métodos no varían en proporciones
signicativas.
Número 20 Vol. 2 (2018)
ISSN 2477-9105
113
V. AGRADECIMIENTO
Al Centro de Investigaciones de Energía
Alternativa y Ambiente de la Espoch,
Facultad de Ciencias.
R
eferencias
1. Hernández E, Duque N, Cadavid J. Big Data: una exploración de investigaciones, tecnologías y
casos de aplicación. TecnoLógicas. 2017.
2. Duque N, Orozco M. Minería de Datos para el Análisis de Datos Meteorológicos. Tendencias en
Ingeniería de Software e Inteligencia Articial. ;: p. 105-114.
3. Segrera S, Moreno M, Miguel L. Aplicación de la minería de datos en la evaluación de la aptitud
física de las tierras para el cultivo de la caña de azúcar. III Taller Nacional de Minería de Datos y
Aprendizaje. 2005;: p. 349-358.
4. Sandoval Z, Prieto F. Caracterización de café cereza empleando técnicas de visión articial.
Facultad Nacional de Agronomía-Medellín. 2007;: p. 4105-4127.
5. Pascual D, Pla F, Sánchez S. Algoritmos de Agrupameinto. Revista Facultad de Ingeniería.
2008;: p. 163-175.
6. Medina R, Ñique C. Bosques Aleatorios como extensión de los árboles de clasicación con los
programas R y Python. Interfases. 2017;: p. 165-189.
7. Robles Y, Sotolongo A. Integración de los algoritmos de minería de datos 1R, PRISM E ID3 A
POSTGRESQL. Gestión de Tecnología y Sistemas de Información. 2013;: p. 389-406.
8. Ochoa L, Paredes K, Araya C. Evaluación de Técnicas de Minería de Datos para la Predicción
del Rendimiento Académico. Global Partnerships for Development and Engineering Education.
2017.
9. Graham W. Data Mining with Rattle and R New York, USA: Springer; 2011.
10. Orozco E, García DA. Métodos de clasicación para identicar lesiones en piel a partir de
espectros de reexión difusa. Revista Ingeniería Biomédica. 2010;: p. 34-40.