
68
ISSN 2477-9105 Número 24 Vol.1 (2020)
R
esumen
Este trabajo usa el concepto de profundidad de datos, así como la carta de control no paramétrica r
desarrollada por Regina Liu, para monitorear el desempeño estudiantil en un grupo de materias en una
institución educativa en un período determinado de tiempo. La metodología usa un conjunto de referencia
obtenido de los resultados mismos en lugar de estándares ideales. Este conjunto de referencia sirve para
calibrar la carta de control y así monitorear datos subsecuentes. El concepto de profundidad de datos
permite crear un índice univariado a partir, en este caso de dos variables, para generar un ordenamiento
de “adentro” hacia “afuera” de la nube de puntos, siendo el punto más central el de mayor profundidad. El
posterior cálculo del rango a partir de las profundidades es la base de la carta r.
Palabras clave: profundidad de datos, cartas de control no paramétricas, educación.
APLICACIONES DE NUEVAS METODOLOGÍAS PARA EL MONITOREO
MULTIVARIADO DEL RENDIMIENTO ESTUDIANTIL UTILIZANDO
GRÁFICOS DE CONTROL Y SISTEMAS UMBRAL
New methodologies applied to multivariate monitoring of student performance using control
charts and threshold systems.
1
Guido Saltos Segura*,
2
Miguel Flores Sánchez,
2
Luis Horna Huaraca,
2
Katherine Morales Quinga
1
Universidad de las Américas, Escuela de Ciencias Físicas y Matemáticas, Quito – Ecuador.
2
Escuela Politécnica Nacional, Facultad de Ciencias, Quito – Ecuador.
*guido.saltos@udla.edu.ec
A
bstract
This paper uses the concept of data depth as well as the nonparametric control chart developed
by Regina Liu, to monitor student performance in a group of subjects at an educational institu-
tion over a given period of time. The methodology uses a reference set obtained from the results
themselves rather than ideal standards. This reference set serves to calibrate the control chart and
therefore monitor subsequent data. The concept of data depth allows creating a univariate index
from, in this case, two variables, to generate an order from "inside" to "outside" the point cloud, the
most central point being the deepest. The subsequent calculation of the range from the depths is
the basis of the chart r.
Keywords: data depth, nonparametric control charts, education
Fecha de recepción: 22-07-2019 Fecha de aceptación: 20-04-2020 Fecha de publicación: 30-07-2020
I. INTRODUCCIÓN
El rendimiento estudiantil ha sido medido tradi-
cionalmente por notas académicas, las cuales han
sido un reejo de los logros estudiantiles en los
diferentes componentes del aprendizaje (1,2). Sin
embargo, varios enfoques diferentes han surgido
en los últimos años, por ejemplo, se ha buscado
explicar el logro de los estudiantes mediante el
uso de grácos de control (3-5), también se pue-
de usar la regresión múltiple y regresión logística
para determinar las variables predictoras del ren-
dimiento académico (6,7). Existen otros trabajos
utilizando modelos de regresión multinivel para
predecir calicaciones nales (8) o modelos de
clasicación para predecir el rendimiento aca-
démico de los estudiantes (9). Por otra parte, los
modelos TOBIT que relacionan características
personales, entorno familiar, etc. con el rendi-
miento académico (10, 11).

69
El presente trabajo pretende mostrar el moni-
toreo del rendimiento estudiantil a lo largo del
tiempo, y realizar el control de calidad para el
análisis de señales tempranas que indiquen que
el resultado del rendimiento no se encuentra en
los límites aceptables de control, permitiendo así
tomar acciones correctivas a tiempo. Además, se
usará el enfoque de monitoreo de dos variables
para poder aplicar el concepto de profundidad de
datos simplicial. Una ventaja del presente méto-
do es que no requiere normalidad en las distribu-
ciones de los datos.
Este trabajo es, además, una aplicación de la me-
todología expuesta en (12) con dos variables, ya
que estudios posteriores han demostrado que la
profundidad simplicial es complicada al trabajar
con más dimensiones (13).
II. MATERIALES Y MÉTODOS
Profundidad de datos
En el análisis multivariante el término profundi-
dad se reere al grado de centralidad de un punto
con respecto a una distribución de probabilidad.
De (13-15) se sigue que, jada una distribución
P en R
d
, una profundidad es una función acotada
D
p
:R
d
→R que asigna a cada punto de R
d
su grado
de centralidad respecto de P.
La profundidad simplicial (SD) es la probabili-
dad de que un punto esté en el simplex, cuyos
vértices son d+1 observaciones independientes
de una distribución P (16-17),
SD(x;P)=Pr{x Î co{X
1
, X
2
,…,X
(d+1)
}} (1)
Donde X
1
, X
2
,…,X
(d+1)
son las observaciones in-
dependientes de P y “co” representa la envolvente
convexa. La versión muestral de la SD se obtiene
reemplazando P por su estimado muestral P
n
o
calculando la fracción de los símplices aleatorios
de la muestra que contienen al punto x.
Grácos de control para procesos multivaria-
dos
Los grácos o cartas de control son herramien-
tas usadas en la industria, ya que, con límites de
control seleccionados adecuadamente, pueden
detectar un desplazamiento de una distribución
de calidad “buena” a una “mala”. Para procesos
multivariados se disponen de varios tipos de
cartas de control (18-21), entre ellas se tienen:
la carta r (usada en este trabajo), la carta Q y la
carta S. La idea principal es reducir cada medi-
da multivariante a su ordenamiento relativo del
centro hacia afuera inducido por profundidad de
datos (22, 23).
Sea k,(k≥1) el número de características de cada
producto usadas para determinar la calidad del
mismo. Sea G la distribución k-dimensional, y
Y
1
,…Y
m
las m observaciones aleatorias de G, la
muestra de referencia, y sean X
1
,X
2
… las nuevas
observaciones provenientes del proceso de ma-
nufactura. Se asume que las X
i
’s siguen una dis-
tribución F. Ahora bien, basado en las observa-
ciones X
i
’s, se quiere determinar si la calidad del
producto se ha deteriorado o si el proceso está
fuera de control. Esto ocurriría si las X
i
’s no si-
guen la distribución G(.). Por tanto, es necesario
comparar las distribuciones F y G.
La profundidad de datos induce un ordena-
miento del centro hacia afuera de los puntos de
la muestra si se calcula la profundidad de todos
los puntos y se los compara. Si se ordenan todas
las profundidades D
G
(Y
i
)’s en orden ascendente
y se usa Y
[j]
para denominar al punto de la mues-
tra asociado con el j-ésimo valor de profundidad
más pequeño, entonces Y
[1]
,Y
[2]
,…Y
[m]
son los es-
tadísticos de orden de los Y
i
’s siendo Y
[m]
el pun-
to más central. Se tiene Y~G, es decir, la variable
aleatoria Y sigue la distribución G, si únicamente
G es desconocida y se tiene la muestra {Y
1
,…Y
m
},
el rango se dene (9):
(3)
Para construir la carta r primero se calcula
{r
G
(X
1
), r
G
(X
2
),…} o {r
G
m
(X
1
),r
G
m
(X
2
),…} usando
la ecuación (3). El proceso es declarado fuera de
control si r
G
(.) cae bajo α.
La carta r, con LCL=α, corresponde a una prueba
de hipótesis de nivel α (18) con H
0
: F=G y H
a
:
existe un desplazamiento de localización y/o un
incremento de escala desde G a F (5). H
0
es re-
chazada cuando una observación cae bajo α. En
(18) se presenta una proposición la cual, bajo la
Saltos, Flores, Horna, Morales
70
ISSN 2477-9105 Número 24 Vol.1 (2020)
hipótesis H
0
, permite justicar la elección de los
límites mencionados para CL=0.5 y LCL=α para
la carta r.
Sistema Umbral
En el conjunto de datos es necesario delimitar un
desempeño medio esperado, para seleccionar el
conjunto de datos esperado, se seguirá el princi-
pio del Clúster Medio mostrado en el trabajo de
(12), el cual establece que el escoger un clúster
medio hace posible identicar en el total, des-
empeños que sean extraordinarios o fuera de lo
ordinario. Por otra parte, en (18) se presenta un
procedimiento de separación y ltrado para con-
gurar el clúster medio. Primero se selecciona el
80% más profundo o más central de los datos y
se forma una región convexa englobando a estas
medidas, luego se considera al 80% de datos más
profundos así seleccionados como el conjunto de
referencia y a su región convexa como el umbral
para identicar desempeños esperados y nal-
mente el 20% restante corresponderá al grupo de
datos no representativos estructurado así: apro-
ximadamente 10% como de atención requerida
y 5% de cada uno de los extremos: inusualmente
buenos o inusualmente malos.
Para efectos de la clasicación del desempeño, se
considerarán los siguientes niveles: esperado, ad-
vertencia, de preocupación e informacional, los
que son detallados en la siguiente sección.
Metodología
En esta sección se describen los datos, posterior-
mente se indica el procedimiento de separación
del conjunto de referencia a ser comparado con
los datos individuales, luego se explica el sistema
umbral y nalmente se muestra el uso de la carta
r. Este procedimiento se realizó en el lenguaje R
con los paquetes qcr y fda.usc (24, 25).
Los datos utilizados en este trabajo provienen
de una institución que ha solicitado no se cite
la fuente, debido a razones de sigilo educativo.
Habrá dos grupos de análisis, el primer grupo de
desempeño promedio por materia, utilizando la
información de 7 materias en el período 2008 -
2015. El segundo grupo analizará el desempeño
individual, es decir trabajaremos con la informa-
ción de 15 estudiantes que cursaron materias de
estadística en el período 2008 - 2011.
Las siglas de las materias son cticias y son las si-
guientes: AES1, AES2, AES3, AES4, AES5, AES6
y AES7. Se utilizarán las variables nota prome-
dio semestral (NPM) y el porcentaje de aproba-
ción de alumnos semestral (PAM).
Los estudiantes se identican con siglas cti-
cias: 8426, 8427, 8509, 6054, 6066, 6166, 6202,
6450, 6515, 6841, 7059, 7060, 7077, 7080, 7091.
Las variables porcentaje de materias aprobadas
(PMAE) y la nota promedio semestral (NPE) de
cada estudiante fueron seleccionadas pues son
variables de interés en otros trabajos realizados.
El procedimiento de separación del núcleo típi-
co que se aplicará a las materias como a los es-
tudiantes es el mismo. Primero se calculan y or-
denan los valores de profundidad simplicial de
todo el conjunto, seguido de la selección del 80%
más profundo y se forma una región convexa a
partir de estas medidas. El conjunto de referen-
cia estará constituido por el 80% central seleccio-
nado de esta manera. Cada materia y estudiante
se compara con este conjunto de referencia para
monitorear el desempeño.
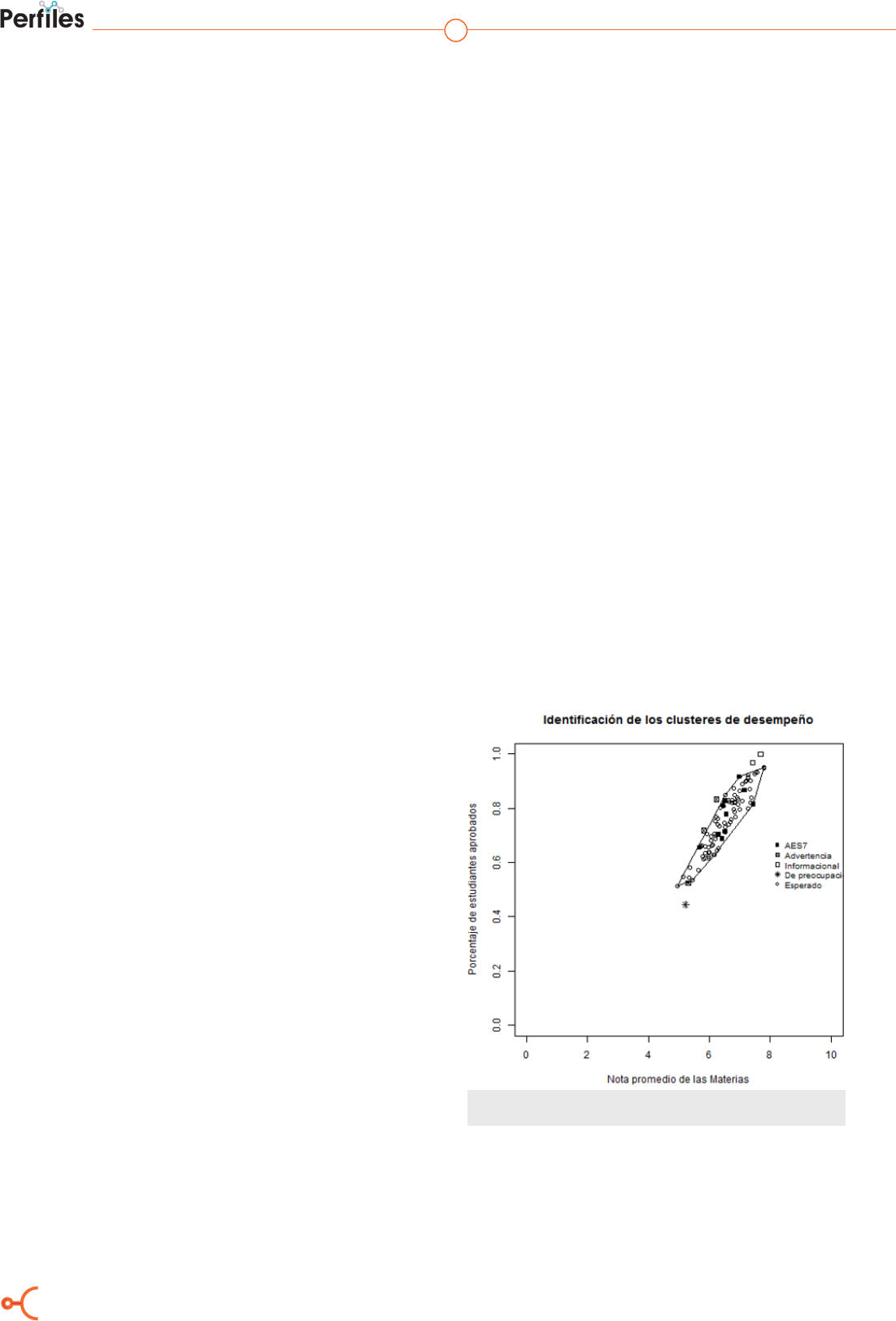
Figura 1. Gráco bivariado de la materia AES7 que representa los grupos
considerados para la clasicación de desempeño dentro de cada materia
A continuación, presentamos el análisis por ma-
terias. Los niveles considerados para la clasica-
ción de desempeño dentro de cada materia son
presentados a continuación y son ejemplicadas
71
en la Figura 1. El nivel esperado, si las dos va-
riables son comparables con el clúster medio (los
círculos blancos dentro de la envolvente conve-
xa). “Advertencia”, si los puntos se alejan un poco
del clúster medio y generalmente una de las dos
variables no es consistente con el conjunto de re-
ferencia (los cuadrados con una x fuera de la en-
volvente convexa). “De preocupación”, los puntos
se alejan más del clúster medio y generalmente
las dos variables son peores que las del conjunto
de referencia (los asteriscos fuera de la envolven-
te convexa). “Informacional”, las dos variables
son mejores que el conjunto de referencia y es-
tán en la parte superior derecha más alejados del
clúster medio (los cuadrados blancos fuera de la
envolvente convexa y en la parte superior de la
misma).
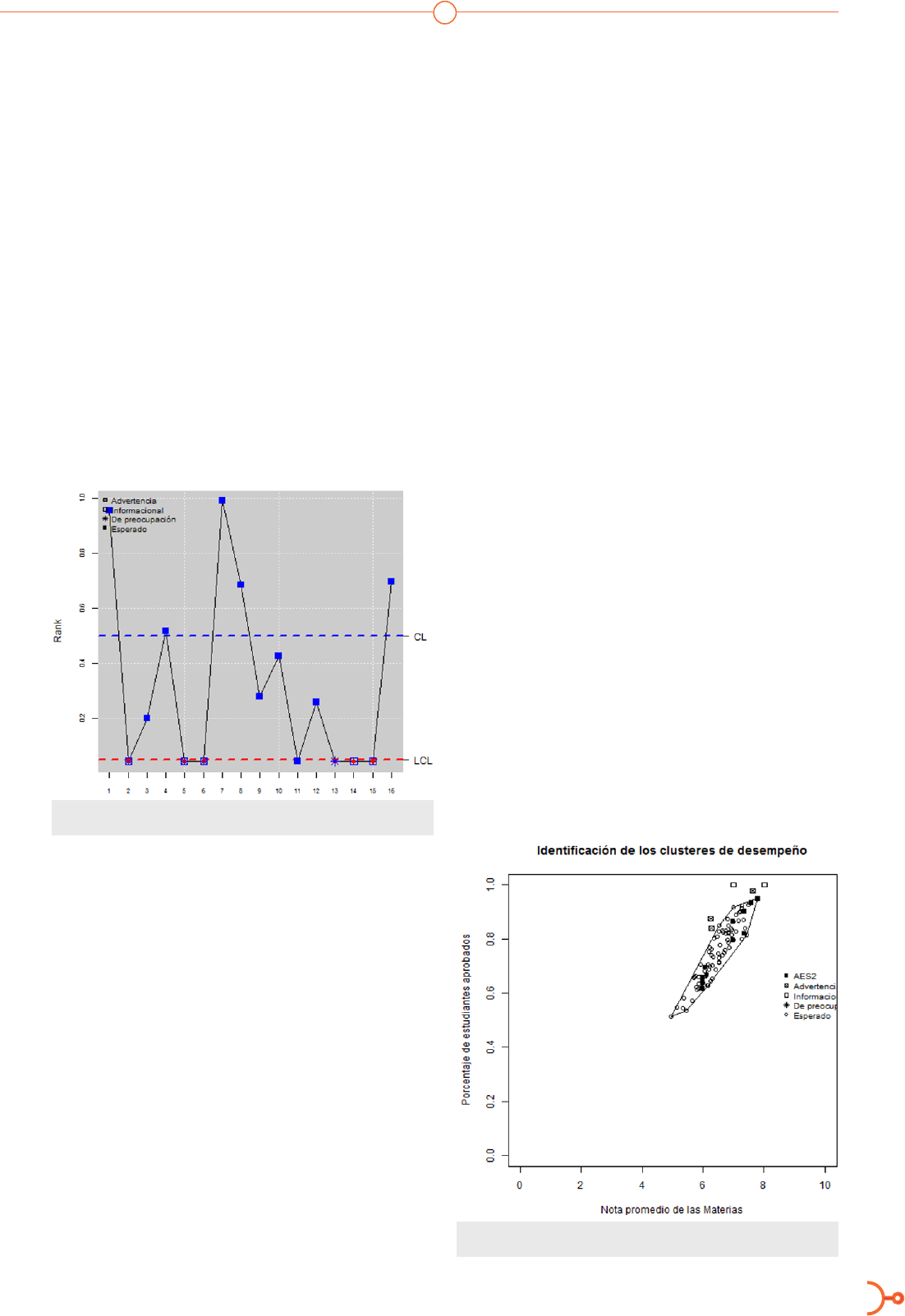
Figura 2. Carta r de la materia AES7 que identica seis puntos fuera de la
envolvente convexa que caen bajo la línea LCL.
Durante el análisis por materias, se aplicará
la carta r para monitorear las variables NPM y
PAM. Los valores de las líneas de control en la
carta r son las siguientes LCL=0.05 y CL=0.5, si
G es la distribución de los datos del clúster me-
dio o esperado, F la distribución monitoreada, se
tiene la hipótesis H
0
: F=G versus H
a
:G≠F. Si r<
α =0.05 puede ser que los puntos corresponden a
las condiciones de preocupación, de advertencia
o informacional.
Por ejemplo, en la Figura 2, la carta r de la misma
materia analizada en la sección anterior; se pue-
den apreciar los seis puntos fuera de la envolven-
te convexa que caen bajo la línea LCL. Estos son:
el 2, 5, 6, 13, 14,15. Hay un punto esperado: el 11
que aparece bajo la línea LCL, pero es debido a
que se encuentra en la frontera de la envolvente
convexa. En todo caso, se mantiene la informa-
ción mostrada en la Figura 1, los puntos 2, 5 y 6
son puntos de advertencia; el 13 es de preocupa-
ción y los puntos 14 y 15 son informacionales.
Un proceso y análisis similar se puede llevar a
cabo para los estudiantes, en este caso se consi-
deran las variables PMAE y NPE.
III. RESULTADOS Y DISCUSIÓN
En esta sección se utilizan los datos de una ma-
teria y de un estudiante para el análisis de los re-
sultados. Primero presentamos un análisis por
materias, más especícamente una comparación
de la materia AES2 con el clúster medio. En la
Figura 3 se aprecia que hay 5 puntos fuera de la
envolvente convexa, siendo tres de advertencia y
dos de ellos informacionales (éstos últimos con
cuadros en blanco). Los de advertencia nos in-
dican que se debe prestar atención al desempeño
de las materias y los informacionales muestran
que ha ocurrido un desempeño superior al de re-
ferencia. Esta información se puede complemen-
tar con la que proporciona la carta r mostrada
en la Figura 4. Además, se puede ver que hay 5
puntos (del 2 al 6) que están por debajo de la lí-
nea LCL, los cuales corresponden a los 5 puntos
mostrados por el gráco bivariado de la Figura 3.
Por otro lado, los puntos 2, 5 y 6 corresponden a
desempeños de advertencia, y el 3 y 4 a mejores
desempeños que el de referencia.
Figura 3. Gráco bivariado de AES2 que representa los grupos considera-
dos para la clasicación de desempeño dentro de cada materia.
Saltos, Flores, Horna, Morales
72
ISSN 2477-9105 Número 24 Vol.1 (2020)
Figura 4. Carta r de la materia AES2,que identica cinco puntos fue-
ra de la envolvente convexa que caen bajo la línea LCL.
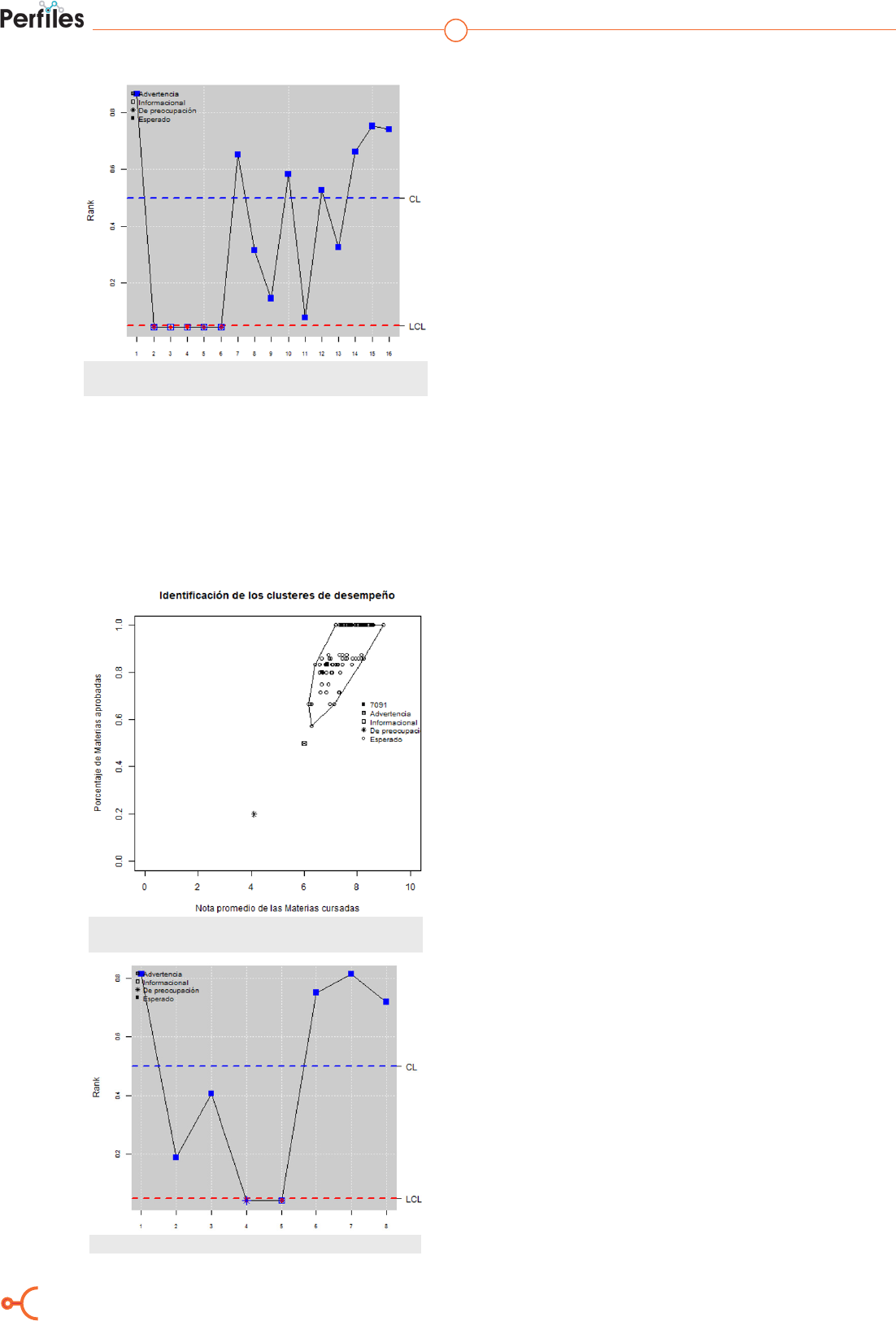
Finalmente, se presenta un análisis por estu-
diante, la Figura 5 muestra la comparación del
estudiante 7091 con el clúster medio en cuanto
al desempeño de las materias cursadas. Se puede
apreciar que hay dos puntos fuera de la envolven-
te convexa: uno de preocupación y uno de adver-
tencia. Lo mismo se puede apreciar en la Figura
6, en la carta r del estudiante.
Figura 5. Comparación del desempeño del estudiante 7091 con el
clúster medio.
Figura 5. Carta r del Estudiante 7091.
IV. CONCLUSIONES
Las herramientas de control de la calidad se pue-
den considerar no solo para monitorizar proce-
sos industriales sino también procesos relaciona-
dos con la educación, por ejemplo, la evaluación
del desempeño estudiantil.
En nuestro caso, para monitorizar varias caracte-
rísticas del desempeño tales como el rendimien-
to, la asistencia a clases y se podrían incluir otras
más. Se utiliza la carta r y se aplica el concepto
de profundidad que transforma una observación
multivariante a un índice univariante, el cual es
susceptible de monitorizar en una carta de con-
trol.
Mediante el sistema Umbral, se pueden identi-
car varios grupos de desempeño y para cada uno
de ellos obtener medidas descriptivas que permi-
tan resumir el perl de los estudiantes.
A partir de estos resultados se pueden plantear
objetivos con la nalidad de poder recongurar
los grupos de desempeño. Por ejemplo, se podría
pensar en estrategias para subir el nivel del rendi-
miento en cada grupo utilizando diferentes me-
todologías de enseñanza.
Respecto a materias y a porcentaje de alumnos
aprobados, el análisis mostró que los datos de las
materias seguían en su totalidad una distribución
normal. Así mismo, las notas promedio de los 15
estudiantes siguen casi en su totalidad distribu-
ciones normales (excepto: 6450 y 6066).
Además, con respecto a los 15 estudiantes en
particular, el análisis mostró que el porcentaje
de materias aprobadas seguía en su mayoría una
distribución no normal. Esto permite ver la e-
cacia de contar con métodos no paramétricos en
los casos donde no se cumple los supuestos de
normalidad.
Las cartas r muestran el desenvolvimiento de las
notas promedio en el tiempo y se ve claramente
la presencia de altos y bajos en el desempeño. Los
puntos extraordinarios brindan oportunidades
de realizar una retroalimentación a estudiantes,
para mejorar o continuar según sea el caso.

73
R
eferencias
1. Garbanzo G. (2013) Factores asociados al rendimiento académico en estudiantes universitarios desde el
nivel socioeconómico: Un estudio en la Universidad de Costa Rica. Revista Electrónica Educare On-line
version ISSN 1409-4258 Educare Vol. 17(3).
2. Collins J., White G., Kennedy J. (1995). Entry to medical school: an audit of traditional selection requi-
rements. Medical Education. Vol. 29(1): 22-28.
3. Okwonu F., Ogini, N. (2017) Application of x and S Control Charts to Investigate Students Performance.
Journal of Advances in Mathematics and Computer Science. Vol. 23(4): 1-15.
4. Beshah B. (2012). Students'' Performance Evaluation Using Statistical Quality Control. International
Journal of Science and Advanced Technology. Vol. 2(12): 75-79.
5. Edwards H., Govindaraju K., Lai C. (2007). A control chart procedure for monitoring university student
grading. International Journal of Services Technology and Management. Vol. 8(4-5), 344-354.
6. Eskew R., Faley R. (1988). Some determinants of student performance in the first college-level financial
accounting course. The Accounting Review. Vol. 63(1): 137-147
7. Barahona P., Aliaga V. (2014) Variables predictoras del rendimiento académico de los alumnos de primer
año de las carreras de Humanidades de la Universidad de Atacama, Chile. Rev. Int. Investig. Cienc. Soc.
Vol. 9(2): 207-220.
8. Montero E., Villalobos J., Valverde A. (2007). Factores Institucionales, Pedagógicos, Psicosociales y
Sociodemográficos asociados al rendimiento académico en la Universidad de Costa Rica: Un análisis Mul-
tinivel. Revista Electrónica de Investigación y Evaluación Educativa. Vol.13(2): 215-234.
9. Pandey M., Taruna S. (2014). A Multi-level Classification Model Pertaining to The Student's Acade-
mic Performance Prediction. International Journal of Advances in Engineering and Technology. Vol. 7(4):
1329-1341.
10. Ferreyra M. (2007). Determinantes del Desempeño Universitario: Efectos Heterogéneos en un Modelo
Censurado. Tesis de Maestría. Maestría en Economía. Universidad Nacional de La Plata.
11. Muhammedhussen M. (2016). Determinants of economics students’ academic performance: Case study
of Jimma University, Ethiopia. International Journal of Scientific and Research Publications. Vol. 6(1): 566-
571.
12. Cheng A., Liu R., Luxhoj J. (2000) Monitoring multivariate aviation safety data by data depth: control
charts and thresholds systems. IIE Transactions 32: 861-872
13. Cascos I.,López A.,Romo J. (2011). Data Depth in Multivariate Statistics. Boletín de Estadística e Inves-
tigación Operativa. Vol. 27(3):151-174.
14. Dyckerhoff, R. (2004). Data depths satisfying the projection property. AStA-Advances in Statistical
Analysis. Vol. 88(2): 163–190.
15. Lange T., Mosler K., Mozharovskyi, P. (2014). Fast nonparametric classification based on data depth.
Statistical Papers. Vol. 55(1): 49-69.
16. Liu R. (1990). On a notion of data depth based on random simplices. The Annals of Statistics. Vol. 18(1):
405-414.
17. Liu, R. Y. (1988). On a notion of simplicial depth. Proceedings of the National Academy of Sciences. Vol.
85(6): 1732-1734.
18. Liu R. (1995). Control Charts for Multivariate Processes. American Statistical Association. Vol. 90(432):
1380-138.
19. Bersimis S., Psarakis S., & Panaretos, J. (2007). Multivariate statistical process control charts: an over-
view. Quality and Reliability engineering international. Vol 23(5): 517-543.
20. Lowry C., Montgomery D. (1995). A review of multivariate control charts. IIE transactions. Vol. 27(6):
800-810.
21. Li Z., Dai Y., Wang Z. (2014). Multivariate change point control chart based on data depth for phase I
analysis. Communications in Statistics-Simulation and Computation. Vol. 43(6): 1490-1507.
22. Liu R., Singh K., Teng J. (2004). DDMA-charts: nonparametric multivariate moving average control
charts based on data depth. Allgemeines Statistisches Archiv. Vol 88(2): 235-258.
23. Liu R., Parelius J., Singh K. (1999). Multivariate analysis by data depth: descriptive statistics, graphics
and inference. The Annals of Statistics. Vol. 27(3), 783-858.
24. Flores M., Naya S., Fernández R. (2014). Quality Control and reliability, (qcr). V01-18. CRAN Reposi-
tory.
Saltos, Flores, Horna, Morales

74
ISSN 2477-9105 Número 24 Vol.1 (2020)
25. Febrero M., Oviedo M. Galeano P.,Nieto A., García-Portugués E. (2015). Functional Data Analysis and
Utilities for Statistical Computing, (fda.usc) V.1.2.2. CRAN Repository